Pca
Contents |
Purpose
Perform principal components analysis.
Synopsis
- pca
- model = pca(x,ncomp,options); %identifies model (calibration step)
- pred = pca(x,model,options); %projects a new X-block onto existing model
Description
Performs a principal component analysis decomposition of the input array data returning ncomp principal components. E.g. for an M by N matrix X the PCA model is 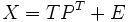 , where the scores matrix T is M by K, the loadings matrix P is N by K, the residuals matrix E is M by N, and K is the number of factors or principal components ncomp. The output model is a PCA model structure. This model can be applied to new data by passing the model structure to PCA along with new data x or by using pcapro.
, where the scores matrix T is M by K, the loadings matrix P is N by K, the residuals matrix E is M by N, and K is the number of factors or principal components ncomp. The output model is a PCA model structure. This model can be applied to new data by passing the model structure to PCA along with new data x or by using pcapro.
Inputs
- x = X-block (2-way array class "double" or "dataset"), and
- ncomp = number of components to to be calculated (positive integer scalar).
Optional Inputs
- model = existing PCA model, onto which new data x is to be applied.
- options = discussed below.
Outputs
The output of PCA is a model structure with the following fields (see Standard Model Structure for additional information):
- modeltype: 'PCA',
- datasource: structure array with information about input data,
- date: date of creation,
- time: time of creation,
- info: additional model information,
- loads: cell array with model loadings for each mode/dimension,
- pred: cell array with model predictions for the input block (when blockdetail='normal' x-block predictions are not saved and this will be an empty array)
- tsqs: cell array with T2 values for each mode,
- ssqresiduals: cell array with sum of squares residuals for each mode,
- description: cell array with text description of model, and
- detail: sub-structure with additional model details and results.
If the inputs are a Mnew by N matrix newdata and and a PCA model model, then PCA applies the model to the new data. Preprocessing included in model will be applied to newdata. The output pred is structure, similar to model, that contains the new scores, and other predictions for newdata.
Note: Calling pca with no inputs starts the graphical user interface (GUI) for this analysis method.
Options
options = a structure array with the following fields:
- display: [ 'off' | {'on'} ], governs level of display to command window,
- plots: [ 'none' | {'final'} ], governs level of plotting.
- outputversion: [ 2 | {3} ], governs output format (discussed below),
- algorithm: [ {'svd'} | 'maf' | 'robustpca' ], algorithm for decomposition, Algorithm 'maf' requires Eigenvector's MIA_Toolbox.
- Algorithm 'maf' requires Eigenvector's MIA_Toolbox.
- preprocessing: {[]}, cell array containing a preprocessing structure (see PREPROCESS) defining preprocessing to use on the data (discussed below),
- blockdetails: [ {'standard'} | 'all' ], level of detail included in the model for predictions and residuals.
- confidencelimit: [ {'0.95'} ], confidence level for Q and T2 limits. A value of zero (0) disables calculation of confidencelimits.
- roptions: structure of options to pass to robpca (robust PCA engine from the Libra Toolbox).
- alpha: [ {0.75} ], (1-alpha) measures the number of outliers the algorithm should resist. Any value between 0.5 and 1 may be specified. These options are only used when algorithm is 'robustpca'.
- cutoff: [] Similar to confidencelimit, this confidence level is used by the robust algorithm to indicate which sample(s) are considered outside the limits and, therefore, likely outliers. It does NOT indicate which samples were actually left out (see alpha above), but only those samples which appear to be more unusual. Default value is the same value as confidencelimit (if non-zero) or alpha (if confidencelimit is zero.)
The default options can be retreived using: options = pca('options');.
OUTPUTVERSION
By default (options.outputversion = 3) the output of the function is a standard model structure model. If options.outputversion = 2, the output format is:
- [scores,loads,ssq,res,reslm,tsqlm,tsq] = pca(xblock1,2,options);
where the outputs are
- scores = x-block scores,
- loads = x-block loadings
- ssq = the sum of squares information,
- res = the Q residuals,
- reslim = the estimated 95Found limit line for Q residuals,
- tsqlim = the estimated 95Found limit line for T2, and
- tsq = the Hotelling's T2 values.
PREPROCESSING
The preprocessing field can be empty [] (indicating that no preprocessing of the data should be used), or it can contain a preprocessing structure output from the PREPROCESS function. For example options.preprocessing = {preprocess('default', 'autoscale')}. This information is echoed in the output model in the model.detail.preprocessing field and is used when applying the PCA model to new data.
See Also
analysis, evolvfa, ewfa, explode, parafac, plotloads, plotscores, preprocess, ssqtable