Advanced Preprocessing: Variable Centering
Contents |
Introduction
Many preprocessing methods are based on the variance in the data. Such techniques should generally be provided with data which are centered relative to some reference point. Centering is generically defined as
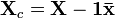
where 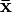 is a vector representing the reference point for each variable,
is a vector representing the reference point for each variable, 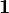 is a column-vector of ones, and
is a column-vector of ones, and 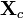 represents the centered data. Often the reference point is the mean of the data. Interpretation of loadings and samples from models built on centered data is done relative to this reference point. For example, when centering is used before calculating a PCA model, the resultant eigenvalues can be interpreted as variance captured by each principal component. Without centering, the eigenvalues include both variance and the sum-squared mean of each variable.
represents the centered data. Often the reference point is the mean of the data. Interpretation of loadings and samples from models built on centered data is done relative to this reference point. For example, when centering is used before calculating a PCA model, the resultant eigenvalues can be interpreted as variance captured by each principal component. Without centering, the eigenvalues include both variance and the sum-squared mean of each variable.
In most cases, centering and/or scaling (see next section) will be the last method in a series of preprocessing methods. When other preprocessing methods are being used, they are usually performed prior to a centering and/or scaling method.
Mean Centering
One of the most common preprocessing methods, mean-centering calculates the mean of each column and subtracts this from the column. Another way of interpreting mean-centered data is that, after mean-centering, each row of the mean-centered data includes only how that row differs from the average sample in the original data matrix.
Mean centering has the effect of including an adjustable intercept in multivariate models. For example, mean-centering both the X and Y blocks in a regression model effectively allows for a non-zero intercept of the regression line. This is critical in many inferential regression problems where the intercept is not necessarily at a Y of zero when X goes to zero (predicting temperature in Kelvin, for example.)
In the Preprocessing window, this method has no adjustable settings. From the command line, this method is achieved using the mncn function.
For more information on the use of mean-centering, see the discussion on Principal Components Analysis in Chapter 5 of the Chemometrics Tutorial.
Median Centering
The median-centering preprocessing method is very similar to mean-centering except that the reference point is the median of each column rather than the mean. This is considered one of the "robust" preprocessing methods in that it is not as influenced by outliers (unusual samples) in the data.
In the Preprocessing window, this method has no adjustable settings. From the command line, this method is performed using the medcn function.
Class Centering
In standard mean centering, the mean of the entire data set (global mean) is removed from all samples. After centering, each sample is relative to the global mean and analyses are of the variance about the global mean. In some cases, subsets of samples may include an offset which is specific to only them but not of interest in the analysis. Such subset-specific offsets will make those groups of samples appear to be different from the other groups which have a different offset. In these cases, class centering can be used to center each group to its local group mean, rather than the global mean. Analyses of class-centered data will examine the variance within the groups of samples and ignore the between-group variations (because all groups have been centered to their own mean giving them all a mean of zero.)
One example of the use of class centering is when multiple samples are measured for each subject in a study (e.g. patients.) For example, if each subject is treated with several different medications and the study wants to know how similar the subject's response is to the medications. In such a case, there may be differences between subjects which are not of interest. Instead, only how each subject changes relative to his or her own mean is what is to be analyzed. This premise has been used in numerous studies and also published under the name Multilevel PLS.
To use class centering, the data being analyzed must have a class set defined in which the samples within each group are given a group-specific class value. Setting these classes is described in the page Assigning Sample Classes. Only the first class set can be used to identify the groups to which class centering should be performed.
In the Preprocessing window, this method has no adjustable settings. From the command line, this method is performed using the classcenter function.
Class Centroid Centering
Standard mean centering calculates the mean of each column in the data set and removes it. If there is a row classset identifying subsets of samples then it might be desirable to calculate the class means, as in "Class Centering" above, but then calculate the mean of these class means, the "class centroid" and remove that from all samples. Samples belonging to class 0 (unknown class) are not used in calculating the centroid or pooled variance.
Class centroid centering is useful for centering to the population mean in cases where the sample subsets represent different population subsets and the subsets are very unbalanced. Using the class centroid avoids the mean being dominated by the most populous subset.
In the Preprocessing window, this method has no adjustable settings. From the command line, this method is performed using the classcentroid function.