Advanced Preprocessing: Variable Scaling
From Eigenvector Documentation Wiki
Contents |
Introduction
Variable scaling is another very common method used with multivariate analysis techniques. Many techniques assume that the magnitude of a measurement is proportional to its importance and that the level of noise is similar in all variables. When variables have significantly different scales simply because they are in different units, the magnitude of the values is not necessarily proportional to the information content. Likewise, scale is also an issue when some variables contain more noise than other variables.
Variable scaling helps address these problems by scaling each variable (column) of a data matrix by some value. The scaling for each variable is presumed to give that variable's information content an equal standing with the other variables. In general this is performed by
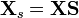
where S is a diagonal matrix of the scaling factors and XS is a matrix of the scaled data. Note that in some cases, scaling will be combined with a centering step, described above.
If scaling is being used, it will be, in general, the final method applied prior to model calculation.
Autoscale
This is an exceptionally common preprocessing method which uses mean-centering followed by division of each column (variable) by the standard deviation of that column. That is, the diagonal of the matrix S in equation above is equal to the inverse of the standard deviation for each column. The result is that each column of XS has a mean of zero and a standard deviation of one.
This approach is a valid approach to correcting for different variable scaling and units if the predominant source of variance in each variable is signal rather than noise. Under these conditions, each variable will be scaled such that its useful signal has an equal footing with other variables' signal. However, if a given variable has significant contributions from noise (i.e., a low signal-to-noise ratio) or has a standard deviation near zero, then autoscaling will cause this variable's noise to have an equal footing with the signal in other variables. This variable may then adversely influence the model. Under these conditions, excluding such variables or using the offset parameter (described below) is recommended.
Autoscaling includes an adjustable parameter "offset" which is added to each column's standard deviation prior to scaling. When offset is non-zero, the diagonal of the matrix S is equal to (s + offset)-1 where s is the vector of standard deviations for each column of X. The offset is useful for de-emphasizing variables which have a standard deviation near zero. By setting the offset to some small value, variables which have standard deviations near or at that level are not as heavily up-scaled. This effectively reduces their influence on a model. The exact level for the offset is largely dependent on the scale and noise level of the data. The default value of offset is zero.
In the Preprocessing window, this method has one adjustable setting for the scaling offset. From the command line, this method is performed using the auto function.
For more information on the use of autoscaling, see the discussion on Principal Components Analysis in Chapter 5 of the chemometrics tutorial.
Group Scale
Similar to autoscaling, group scaling performs scaling based on standard deviations. Group scaling is often used when the data consist of several equal-sized blocks of variables. Each block contains variables in some given unit of measure, but different blocks use different units. This kind of situation occurs in Multiway Principal Components Analysis (MPCA).
Group scale is performed by splitting the variables into a predefined number of equally-sized blocks and scaling each block by the grand mean of their standard deviations. For each block, the standard deviations for each variable in a block are calculated and the mean of those standard deviations is used to scale all columns in the block. The same procedure is repeated for each block of variables. By default, the group scale method assumes that all blocks have an equal number of columns.
Group scaling when different numbers of variables are in each group can achieved by assigning "class" labels to the variables (columns) of the X-block. Variables which are in a single group should be given the same class identifier. These classes can be used to do group scaling by providing the class set (usually set 1) as a negative integer in place of the "number of blocks" setting of Group Scale (see below).
In the Preprocessing window, this method has one adjustable parameter indicating the number of blocks to split the variables into. If set to zero, the method will attempt to infer the number of blocks from the size of the original data (if a three-way matrix). When a negative value is provided for number of blocks, it is assumed to refer to a class set on the variables which should be used to split variables up into blocks. From the command line, this method is performed using the gscale function.
Log Decay Scaling
Log decay scaling is typically used in Mass Spectrometry (MS) and is a first-principle alternative to autoscaling for MS data. The scaling is based on the assumption that, in some types of instrumentation, the sensitivity of the instrument is roughly logarithmically proportional to the size of the mass fragment. The larger the mass, the less sensitive the instrument and the lower the counts for the given mass. Log decay scaling attempts to correct for this insensitivity to larger masses by scaling each mass by a continuously decreasing log function of the form:
- si = e − i / nτ
where si is the scaling for variable i (sorted in order of increasing mass), n is the total number of variables and τ (tau) is an adjustable parameter defining the differential scaling of early masses to later masses. The smaller the value for τ, the more the larger masses are up-scaled relative to the smaller masses. Selection of τ largely depends on the instrumentation and the insensitivity to larger masses. The default value for τ is 0.3.
Note that, unlike autoscaling, this method does not mean-center the data.
In the Preprocessing window, this method allows for adjustment of τ in the settings. From the command line, this method is performed using the logdecay function.
Poisson (Sqrt Mean) Scaling
In many cases, the goal of scaling is to adjust the magnitude of each variable so that the level of noise is equal in all variables. In cases where the noise is approximately proportional to the square root of the signal in each variable, Poisson scaling (also known as square root mean scaling or "sqrt mean scale") can be used. This method scales each variable by the square root of the mean of the variable. If the predominant noise source is truly proportional to the square root of the signal, this effectively corrects all variables to the same level of noise.
An offset is often used to avoid over-emphasizing variables with near-zero means (which would otherwise be divided by an exceptionally small number). This offset is defined in terms of a percent of the maximum of all variables' means. An offset of 1-5% is typically used and a value of zero implies no offset should be used.
This method has been used effectively to correct Mass Spectra (Keenan and Kotula, 2004) but is also valid in other spectroscopies or measurements where noise is likely to be shot-noise limited (low light luminescence and Raman spectroscopies, for example). Note that, unlike autoscaling, this method does not mean-center the data.
In the Preprocessing window, the offset is the only adjustable parameter. At the command line, the poissonscale function performs this operation.
Pareto (Sqrt Std) Scaling
This method is similar to the Poisson scaling method and is used when noise is expected to be proportional to the square root of the standard deviation of the variables. Like Poisson scaling, it does not mean-center the data. Unlike Poisson scaling, Pareto scaling does not offer the use of an offset.
In the Preprocessing window, there are no adjustable parameters. There is no single function to perform this operation at the command line, but the following duplicates the calculation:
[junk,junk,stdev] = auto(data); data = scale(data,stdev*0,sqrt(stdev));
Variance (Std) Scaling
This method is nearly identical to autoscaling and is used for the same reason (when noise is expected to be proportional to the standard deviation of the variables), but unlike autoscaling, this method does not mean-center the data.
In the Preprocessing window, there are no adjustable parameters. There is no single function to perform this operation at the command line, but the following duplicates the calculation:
[junk,junk,stdev] = auto(data); data = scale(data,stdev*0,stdev);